Problem:
I’d like to optimize the deployment of the content-app, without overloading the system
Expected outcome:
Better understanding of the resource requirements of the content app and recommendations how to scale it
Pulpcore version:
3.21.5
Pulp plugins installed and their versions:
- rpm 3.18.11
- file 1.11.1
- container 2.14.3
- certguard 1.5.5
- ansible 0.15.0
Operating system - distribution and version:
RHEL 8.8
Other relevant data:
Hi!
We’re running Pulpcore 3.21 as part of a Katello 4.7 deployment, which is mostly used to sync RHEL and CentOS RPM repositories and serve them to clients (no containers, no ansible, but a few files are present).
The machine has 16 cores and 32GB RAM, and has been struggling with the API memory leak, which prompted me to also look at the content app. (No need to worry, I don’t think the content app leaks memory, but I still would like to better understand how it uses it).
The content app gets configured with 17(!) workers on that box by the installer:
The number is based on the Gunicorn docs, which recommend 2×CPU+1 while at the same time saying that 4-12 should be enough in most cases.
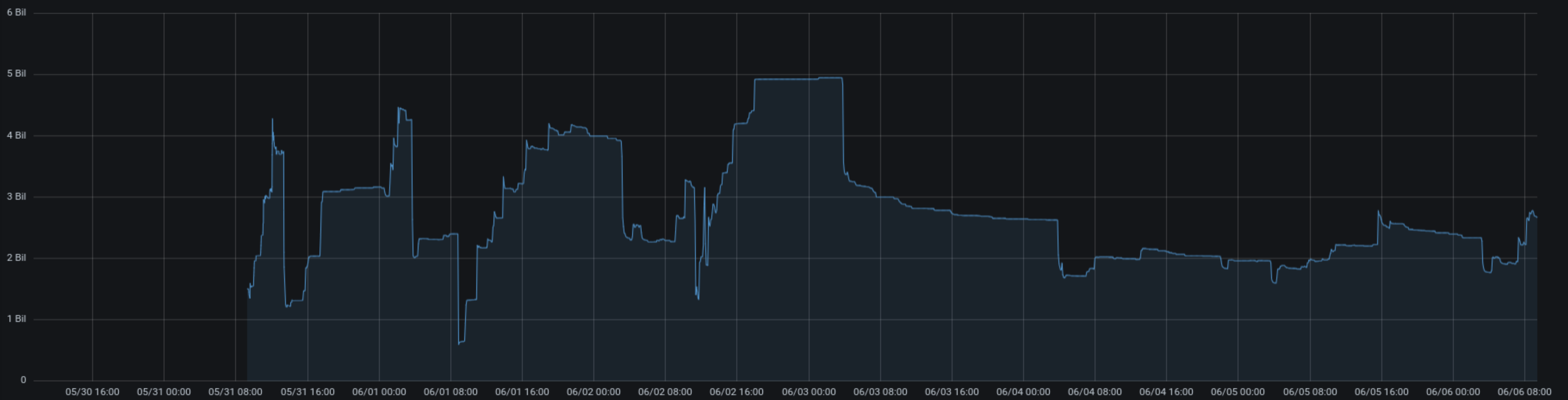
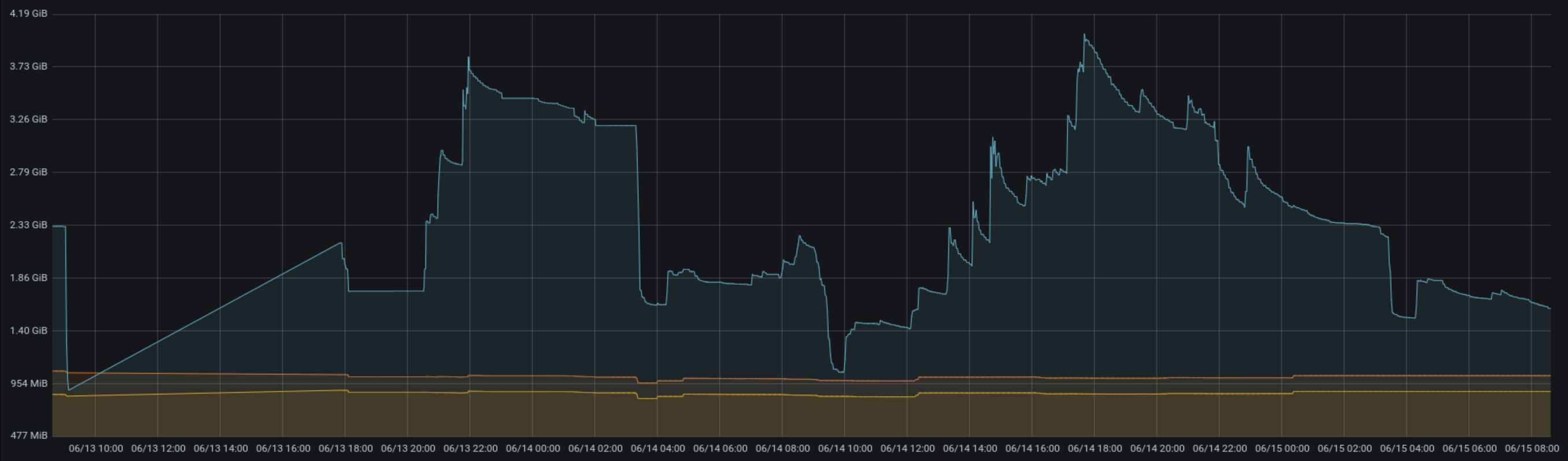
I’ve been watching the memory usage of that setup in the recent days, and seen it peaking at roughly 4.25GB (= 250MB per worker). When looking closer at the usage changes and correlating them with logs, it seems that when the app serves many RPMs “at the same time” (think of a downstream consumer downloading many packages) the memory usage spikes up, while it falls down when many repodata files are transferred.
With that observation in mind, I came to the following questions:
- Should that setup run with fewer wokers? My gut feeling is to half the number and see how it works out?
- Should we apply the same “max requests” recycling as we do with API workers? Probably at different limits then (max 500, jitter 50?)…
- The grow/shrink timing above hints that the memory is “recycled” when a new (smaller) file is served and not when the big file finished transferring. Can we improve this behaviour?