Yay folks! Hey, we’ve been running our instance for some time and we would like to share some info and ask for some collaboration in the discussion of some items.
Before anything, our Pulp instance runs on a Openshift/Kubernetes cluster, and it manages almost 20TB of artifact data, our DB uses 1.5 TB at least, and currently we run 24 pulp-workers, with an intent to scale it to 48 workers. I can’t say this is the biggest Pulp instance in the world, but we’re on the run for it. 
After some heavy load tests and gathering some data, we had some impressions about the tasking system:
-
Upper limit of how many workers we can start (assume completely idle system)
1.1 Limited by the number of sessions opened to the database
1.2 Limited by the number of heartbeats that can be written before workers start timing out. -
Upper limit of how concurrency of task dispatching / insertion
2.1 Throughput is limited by this lock acquisition. -
Upper limit of tasks we process (assuming infinite workers)
3.1 Limited by the architecture of the advisory lock concurrency -
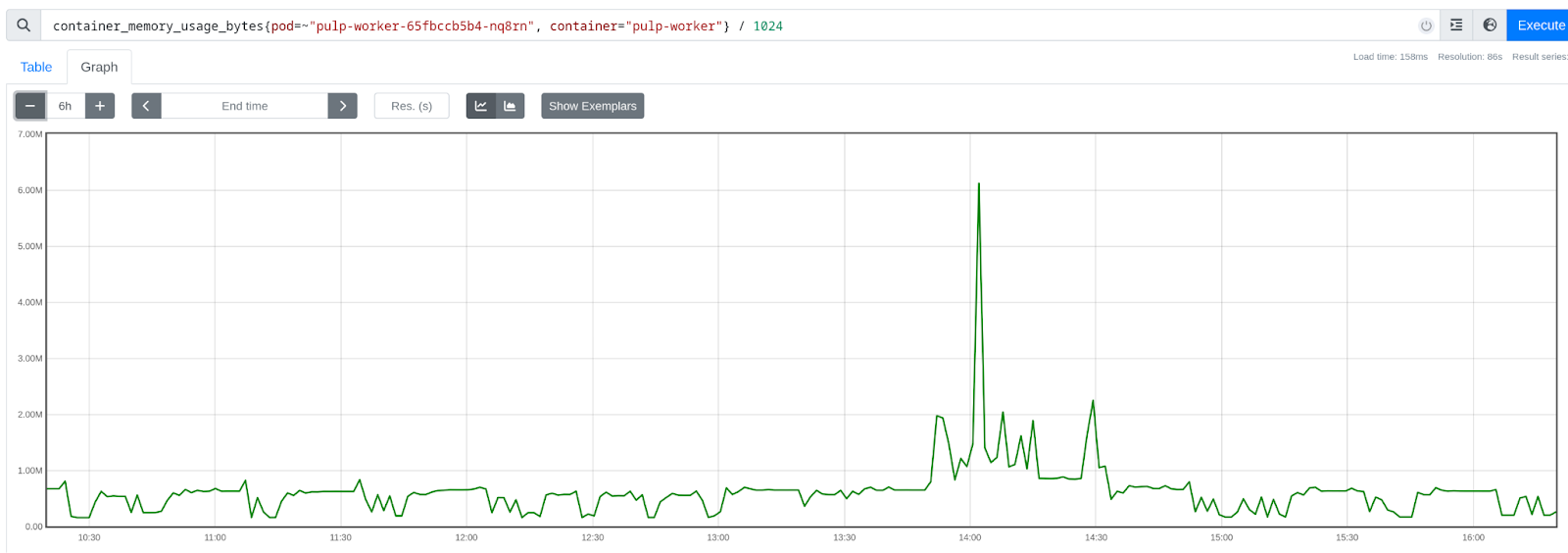
Cost due to memory footprint
4.1 Workers need a huge amount of memory. We set the base memory as 2GB, and the upper limit to 6GB.
4.2 Things that need that upper limit are not garantee to run, it could be killed by the scheduler. -
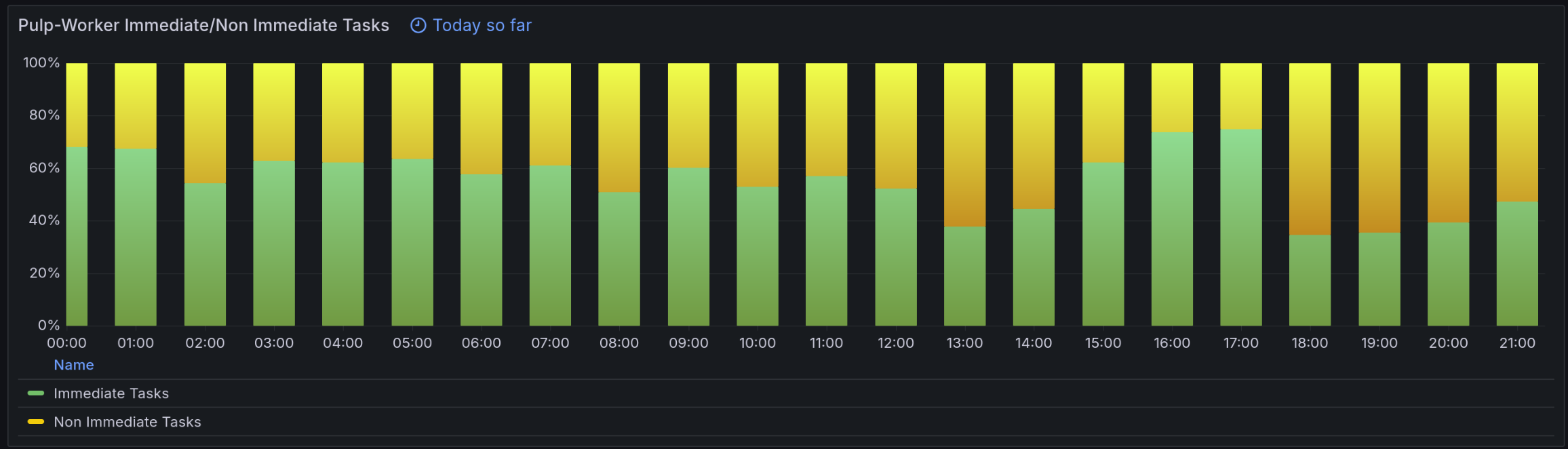
Not clear which feature set for immediate task scheduling we are using now
5.1 Which of our tasks are immediate ones? Where and how those immediate tasks run? -
Tasking logging is not exactly a standard
6.1 Task logs doesn’t necessarily have a task id, so it’s hard to correlate log entries.
6.2 It’s not clear what the tasking system started to run or completed using the logs.
Creating a Tasking working group to discuss those things would be great.
So, I want to hear from you:
- Do you share some of those impressions?
- Would you want to work on any of those points?
- Do you have any insight about it?
PS: Feel free to ask for more data if it could support the discussion here. We’ll work to get it ASAP.